
Xiaoqian Shen
About Me
I am currently a PhD student of Computer Science at King Abdullah University of Science and Technology (KAUST) supervised by Mohamed Elhoseiny. Before that, I received BSc in Computer Science from Jilin University, China. I have been fortunate to develop research and industry experience through internships at Meta and Nvidia.
Research Interests
-
Generative Models — Image & Video Generation
MoStGAN-VCVPR StoryGPT-VCVPR -
Vision-Language — Multi-Modal Comprehension
VisReflectECCV VgentNeurIPS🌟 LongVUICML MiniGPT-4ICLR
News
- Jun 2026Two papers (VisReflect, HybAdv) get accepted to ECCV’26 🎉
- Sep 2025One paper (Vgent) gets accepted to NeurIPS’25 (Spotlight) 🎉
- May 2025One paper (LongVU) gets accepted to ICML’25 🎉
- Feb 2025One paper (StoryGPT-V) gets accepted to CVPR’25 🎉
- Jul 2024Two papers (GoldFish, AffectVisDial) get accepted to ECCV’24
- Mar 2024One paper (HyperCGAN) gets accepted to CVPR’24
- Jan 2024One paper (MiniGPT-4) gets accepted to ICLR’24
- Nov 2023Successfully defended my Master thesis
- Jul 2023One paper (HRS-Bench) gets accepted to ICCV’23
- Feb 2023One paper (MoStGAN-V) gets accepted to CVPR’23
- Sep 2022Started my Master journey at KAUST
- Jul 2022One paper (HGR-Net) gets accepted to ECCV’22
- Dec 2021Joined Vision-CAIR at KAUST as a visiting research student
Experience
-
 Jun 2026 – Oct 2026Research Scientist Intern, Meta
Jun 2026 – Oct 2026Research Scientist Intern, Meta -
 Jun 2025 – Sep 2025Research Intern, Nvidia
Jun 2025 – Sep 2025Research Intern, Nvidia -
May 2024 – Nov 2024Research Scientist Intern, Meta
-
 Dec 2021 – Mar 2022Visiting Research Student, KAUST
Dec 2021 – Mar 2022Visiting Research Student, KAUST -
 Dec 2020 – Mar 2021Research Assistant, Tsinghua University
Dec 2020 – Mar 2021Research Assistant, Tsinghua University
Selected Publications [ Google Scholar]
-
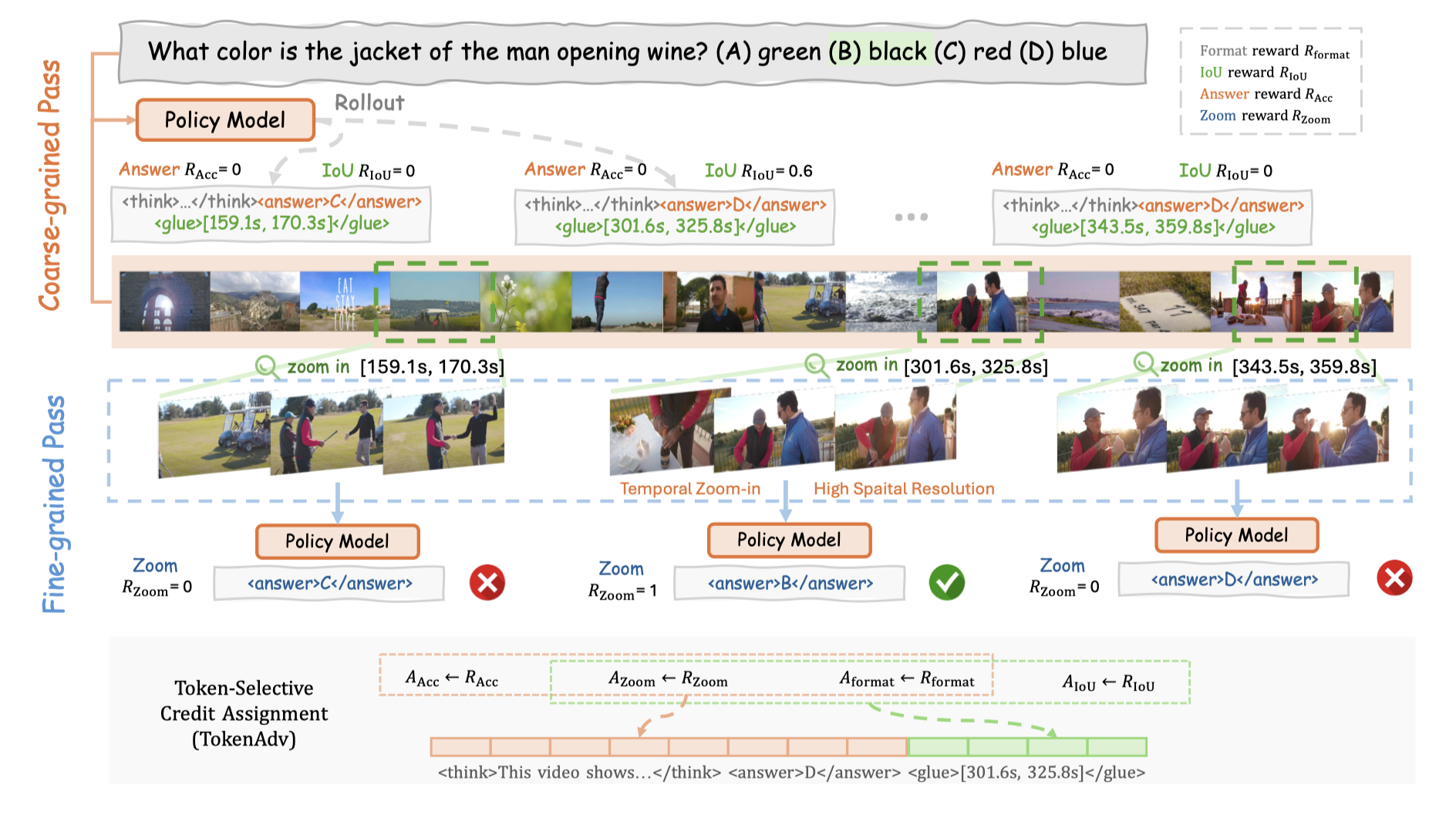
Preprint ICLR 2026 Workshop on Multimodal Intelligence -
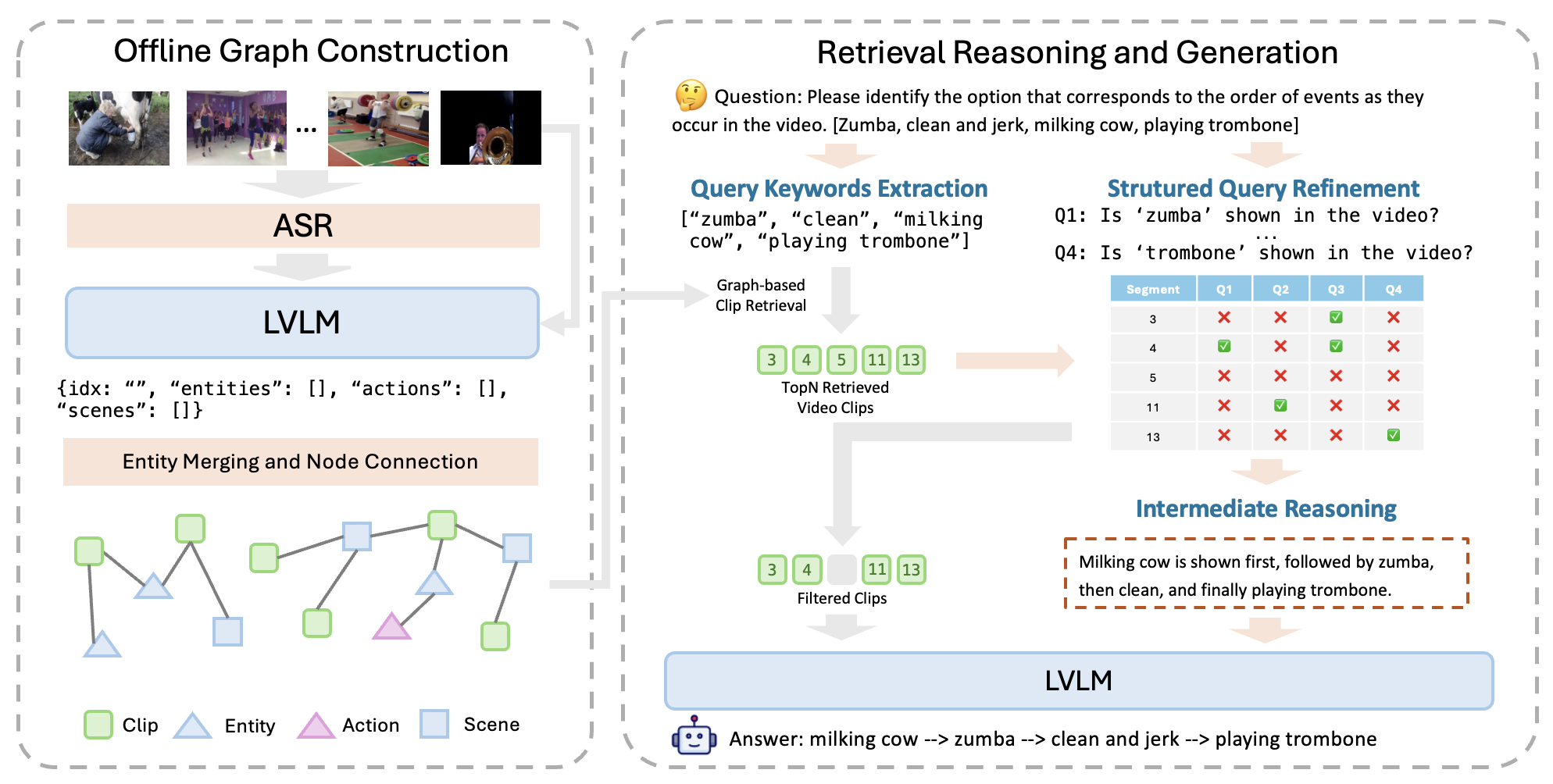 NeurIPS
NeurIPS 2025
NeurIPS
NeurIPS 2025 -
 ICML
ICML 2025
ICML
ICML 2025 -
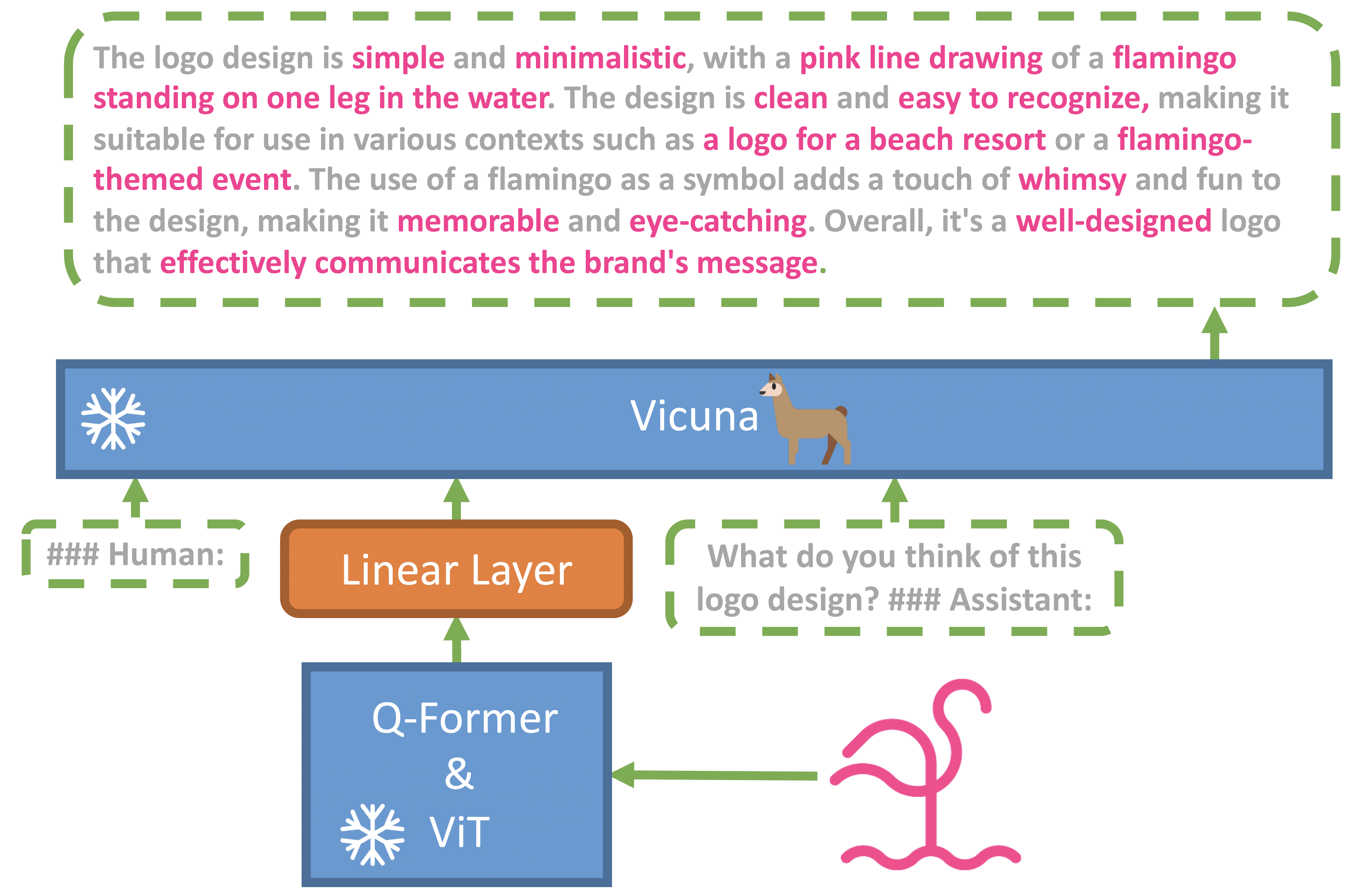 ICLR
ICLR 2024
ICLR
ICLR 2024
 ECCV
ECCV
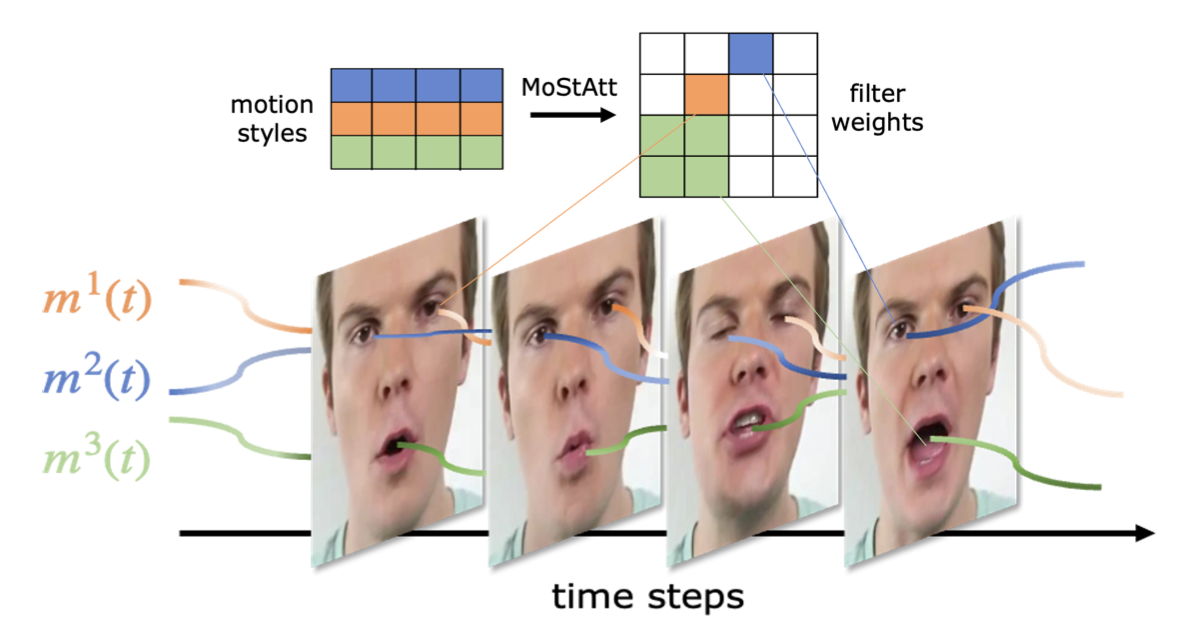 CVPR
CVPR
Services
Conference Reviewers
- CVPR, ECCV, AAAI, ICLR, ICCV
- SIGGRAPH Asia, NeurIPSW
Journal Reviewers
- IJCV, CVIU, TMM, TPAMI
Teaching Assistant
- KAUST CS 283 Deep Generative Modeling
Powered by Jekyll and Minimal Light theme.